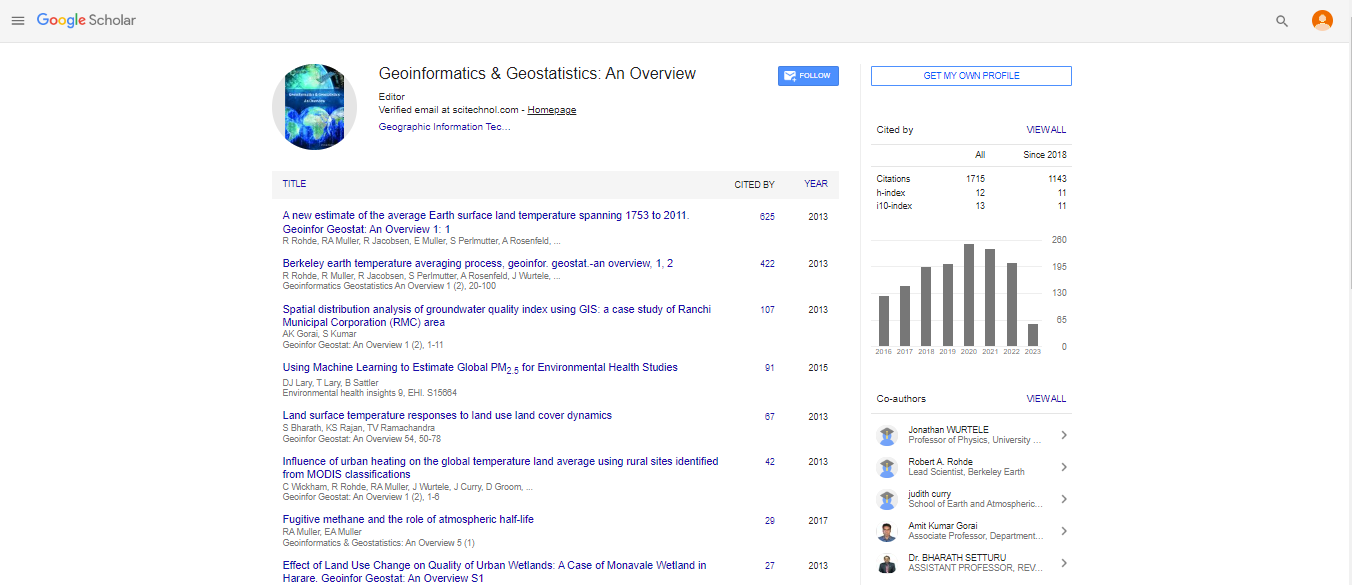
Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi Commentary, Geoinfor Geostat An Overview Vol: 12 Issue: 5
Evaluating different Machine Learning Techniques for Spatial Interpolation of Environmental Data
Isla Tanaka*
1Department of Geospatial Sciences, National University of Singapore, Singapore City, Singapore
*Corresponding Author: Isla Tanaka,
Department of Geospatial Sciences, National
University of Singapore, Singapore City, Singapore
E-mail: tanakaisla@nuss.edu.sg
Received date: 23 September, 2024, Manuscript No. GIGS-24-150259;
Editor assigned date: 25 September, 2024, PreQC No. GIGS-24-150259 (PQ);
Reviewed date: 09 October, 2024, QC No. GIGS-24-150259;
Revised date: 16 October, 2024, Manuscript No. GIGS-24-150259 (R);
Published date: 23 October, 2024, DOI: 10.4172/2327-4581.1000414
Citation: Tanaka I (2024) Evaluating different Machine Learning Techniques for Spatial Interpolation of Environmental Data. Geoinfor Geostat: An Overview 12:5.
Abstract
Spatial interpolation is an important technique in environmental science, enabling the estimation of unmeasured values based on known data points. This is particularly important for understanding environmental phenomena such as air quality, temperature variations and pollutant levels, which are often collected at discrete locations. Traditional interpolation methods, such as Kriging and Inverse Distance Weighting (IDW), have been widely used; however, they may not always capture the complexities of spatial patterns effectively. With the advent of Machine Learning (ML), there is significant potential to improve interpolation accuracy. This essay evaluates various machine learning techniques, including Random Forest, Support Vector Regression (SVR) and Artificial Neural Networks (ANN), for their effectiveness in spatial interpolation of environmental data.
Description
Spatial interpolation is an important technique in environmental science, enabling the estimation of unmeasured values based on known data points. This is particularly important for understanding environmental phenomena such as air quality, temperature variations and pollutant levels, which are often collected at discrete locations. Traditional interpolation methods, such as Kriging and Inverse Distance Weighting (IDW), have been widely used; however, they may not always capture the complexities of spatial patterns effectively. With the advent of Machine Learning (ML), there is significant potential to improve interpolation accuracy. This essay evaluates various machine learning techniques, including Random Forest, Support Vector Regression (SVR) and Artificial Neural Networks (ANN), for their effectiveness in spatial interpolation of environmental data.
Methodologies in spatial interpolation
Traditional interpolation methods have long been the fundamental of spatial analysis. Kriging is a geostatistical technique that takes into account the spatial autocorrelation of data points. It uses a variogram to model the spatial structure of the data, providing predictions that are statistically optimal. Inverse Distance Weighting (IDW) is a deterministic method that estimates values at unmeasured locations by averaging nearby points, with closer points weighted more heavily. While straightforward, IDW may oversimplify spatial relationships and fail to account for complex patterns. In contrast, machine learning techniques offer a more flexible approach to interpolation.
Random Forest (RF): An ensemble learning method that constructs multiple decision trees during training and outputs the average prediction. RF is known for its robustness and ability to handle highdimensional data without requiring extensive preprocessing.
Support Vector Regression (SVR): An adaptation of Support Vector Machines for regression tasks, SVR seeks to find a hyperplane that best fits the training data. It is particularly effective for capturing non-linear relationships in complex datasets.
Artificial Neural Networks (ANN): Inspired by biological neural networks, ANNs consist of interconnected nodes organized in layers. They are capable of learning complex patterns and relationships within the data, making them suitable for various types of spatial interpolation.
Comparative evaluation
The effectiveness of these techniques can be evaluated based on several criteria: Accuracy, computational efficiency and ease of implementation.
Accuracy: Machine learning techniques generally outperform traditional methods in terms of accuracy. Studies have shown that RF can achieve lower Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) compared to Kriging and IDW. This improved accuracy stems from RF's ability to model complex interactions between variables and its resilience to overfitting.
Computational Efficiency: While traditional methods often require less computational power, machine learning techniques, particularly RF and ANN, can be resource-intensive. However, advancements in computing power and algorithm optimization have made these methods more accessible, allowing for their application in larger datasets and real-time analysis.
Ease of implementation: Traditional methods are generally easier to implement and interpret, particularly for researchers without extensive machine learning expertise. In contrast, while ML techniques may require a more sophisticated understanding of model tuning and validation, tools and libraries such as Scikit-learn and TensorFlow have made implementation more straightforward.
Several case studies illustrate the advantages of machine learning techniques in spatial interpolation. For instance, research has shown that RF significantly improved the accuracy of air quality predictions in urban environments compared to traditional methods. Similarly, SVR has been effectively employed to interpolate rainfall data across heterogeneous landscapes, capturing complex spatial patterns that traditional methods failed to address.
In a study focused on temperature mapping, ANNs outperformed Kriging, demonstrating their capacity to model non-linear relationships in spatial data. These case studies shows the potential of machine learning techniques to provide more accurate and reliable spatial interpolations in various environmental contexts.
Despite their advantages, machine learning techniques also face challenges. One primary concern is the interpretability of models. While RF and ANN can yield high accuracy, their "black box" nature can make it difficult to understand the underlying processes driving predictions. This lack of transparency can be a barrier in fields like environmental science, where understanding the relationships between variables is important.
Moreover, the choice of features and model parameters can significantly impact performance. Researchers must carefully select relevant variables and tune hyperparameters to achieve optimal results. This process often requires extensive experimentation and validation, which can be resource-intensive.
Conclusion
The evaluation of machine learning techniques for spatial interpolation of environmental data reveals significant advantages over traditional methods. Techniques such as random forest, support vector regression and artificial neural networks offer improved accuracy and the ability to capture complex spatial patterns. As computational resources become more accessible and user-friendly tools proliferate, the application of machine learning in spatial interpolation is likely to grow. While challenges such as model interpretability and feature selection remain, the potential benefits of enhanced accuracy and adaptability make machine learning an exciting frontier for environmental data analysis. As the field evolves, integrating these advanced techniques with traditional methods may provide the best of both worlds, leading to more effective environmental monitoring and management strategies.